Áp dụng các phương pháp xử lý dữ liệu xây dựng hệ tri thức chuyên gia Việt
- Thứ năm - 28/07/2022 21:39
- |In ra
- |Đóng cửa sổ này


Từ hàng thập kỷ qua, hàng trăm ngàn chuyên gia người Việt, gốc Việt đã và đang làm việc, nghiên cứu tại nhiều quốc gia phát triển. Đây là nguồn tài nguyên quý giá và quan trọng cho sự phát triển của đất nước nếu được tập hợp và phát huy đúng cách. Để xây dựng một nền kinh tế vững mạnh dựa trên công nghệ, kỹ thuật tiên tiến rất cần một cơ sở dữ liệu chuyên gia người Việt trên toàn cầu. Với mục đích xây dựng một nền tảng tìm kiếm và phân tích thông tin về Chuyên gia Việt tại các quốc gia có nền kinh tế, khoa học, công nghệ phát triển, dự án BDAVO do trường Đại học Kinh tế Quốc dân hợp tác với Công ty giải pháp công nghệ VietSearch với sự tài trợ của Quỹ Đổi mới sáng tạo Vingroup (VINIF) đã được triển khai.
Hiện tại, dòng luân chuyển của người Việt khi tìm việc và học tập tại nước ngoài cũng như về nước làm việc ngày càng lớn. Điều đó càng cho thấy sự cấp thiết của một cơ sở dữ liệu chuyên gia người Việt như BDAVO.
Để đáp ứng được những mong mỏi này, BDAVO tập trung vào mảng tổng hợp và xử lý dữ liệu từ nhiều nguồn trong việc khai thác và kết nối chuyên gia người Việt và gốc Việt ở nước ngoài. Dự án nghiên cứu và ứng dụng một số công nghệ Big Data (dữ liệu lớn), Data Mining (khai phá dữ liệu), Data Analytics (phân tích dữ liệu), Machine Learning (học máy)… để tạo nên một nền tảng phát hiện nguồn lực chất lượng cao tiềm năng cho Hệ sinh thái Đổi mới sáng tạo ở Việt Nam.
Thông thường, một nền tảng tìm kiếm và phân tích thông tin gồm một số thành phần chính là: (1) Thu thập dữ liệu từ nhiều nguồn; (2) Chuẩn hóa, làm sạch, làm giàu dữ liệu, bóc tách thuộc tích, phân lớp dữ liệu; (3) Đánh chỉ số, phân thứ hạng cho dữ liệu để hỗ trợ việc tìm kiếm; (4) Các thuật toán hỗ trợ khớp, xếp hạng, gợi ý dữ liệu liên quan khi có truy vấn; (5) Hệ thống giao diện và hiển thị thông tin cho người dùng; (6) Hệ thống quản trị nội dung, quản trị tri thức để có sự tương tác, can thiệp của con người hỗ trợ cho các hệ thống xử lý tự động.
Ngoài ra hệ thống cần một cơ sở hạ tầng lưu trứữvà xử lý dữ liệu phân tán vì thường lượng dữ liệu khá nhiều và phải xử lý liên tục và nhanh nên sẽ hạn chế nếu chỉ chạy trên một máy, chẳng hạn có sự thay đổi về lược đồ dữ liệu, bắt buộc phải xử lý lại toàn bộ dữ liệu để đáp ứng lược đồ mới. Xử lý toàn bộ dữ liệu mất 8h trên một máy thì coi như mất một ngày làm việc đợi có hết kết quả. nếu chạy đồng thời bốn máy chỉ mất 2h thì sớm có kết quả để kiểm nghiệm trong ngày luôn.
Hệ thống BDAVO được thiết kế để đáp ứng đầy đủ các yêu cầu trên.
Kiến trúc xử lý dữ liệu của hệ thống BDAVO có thể khái quát trong hình 1 với 3 module chính (1) thu thập dữ liệu Chuyên gia (2) xử lý dữ liệu Chuyên gia (3) tìm kiếm và gợi ý dữ liệu Chuyên gia.
Do dữ liệu ban đầu của hệ thống BDAVO là nguồn dữ liệu “thô” thu thập từ nhiều nguồn trên Internet nên để có được các dữ liệu “tinh” hỗ trợ cho các tính năng tìm kiếm, gợi ý chuyên gia, một số phương pháp Xử lý dữ liệu được trình bày ở đây.

Phát hiện chuyên gia Việt trong hệ thống dữ liệu lớn toàn cầu
Về tổng quan, khó khăn chính mà chúng tôi gặp phải khi phát triển BDAVO là thu thập dữ liệu. Thường dữ liệu tản mát thì việc thu thập, chuẩn hóa mất rất nhiều thời gian. Dữ liệu tập trung của một số hệ thống có sẵn như Linkedin thì họ sẽ chặn và không muốn cho các hệ thống khác thu thập dữ liệu từ phía họ. Đây là một sự thiệt thòi cho Việt Nam bởi nếu không phát triển được các nền tảng quản lý dữ liệu của nước mình vì các “tài nguyên” thông tin của Việt Nam (ví dụ như thông tin của một chuyên gia người Việt) lại do nước ngoài nắm giữ, khi mình muốn sử dụng cho một số mục đích cụ thể cũng rất khó khai thác, ngay cả để phục vụ cộng đồng.
Mặt khác, khi thu thập dữ liệu về chuyên gia, thường chúng ta quan tâm đến các nền tảng cung cấp nhân lực lao động, ví dụ như LinkedIn. Khi đó, các máy tìm kiếm các nhà khoa học chuyên gia như Google Scholar, Research Gate, các xuất bản online, những danh bạ điện thoại tại các quốc gia trên thế giới v.v…. Khi phải xử lý hàng chục triệu bản ghi dữ liệu trên Internet từ nhiều quốc gia, ngôn ngữ khác nhau thì việc phân biệt tự động đâu là tên người gốc Việt là thách thức trước tiên trong việc xây dựng một Cơ sở tri thức Chuyên gia Việt. Là một người Việt Nam, khi đọc tên ai ta có thể có cảm nhận đó có phải là người gốc Việt hay không. Ví dụ một người họ Nguyễn rất dễ nhận là người gốc Việt. Tuy nhiên có những họ rất thông dụng của Việt nam như “Lê” khi viết không dấu bị lẫn với giới từ thông dụng nhất của tiếng Pháp là “Le”. Hay các họ tên nghe rất Việt như “Vân” khi viết không dấu lại lẫn với tên “Van” thông dụng trong tiếng Hà Lan. Ngoài ra các nước châu Á như Hàn Quốc, Đài Loan, Thái Lan, Trung Quốc, Singapore phần tên có rất nhiều từ giống tên Việt Nam khi biểu diễn bằng chữ cái Latin với các ký tự không dấu ASCII.
Do vậy, nhóm nghiên cứu của dự án BDAVO đã tạo ra phương pháp phát hiện tên người Việt của riêng mình dựa trên:
– Thống kê tên người Việt từ một nguồn có hơn 500.000 tên Việt
– Tạo cây quyết định dựa trên các thống kê unigram, bigram (e.g. “le thi”, “thanh van”, …), n-grams
– Áp dụng các phương pháp loại trừ dựa trên một số tập dữ liệu tên người nước ngoài.
Cây quyết định phát hiện tên người Việt được mô tả trong hình 2:

Việc quyết định tên có chắc chắn là người Việt không dựa trên tập dữ liệu huấn luyện. Do tên người Việt có trung bình ba từ nên cây quyết định này có độ sâu thấp, chỉ cần dùng đến Trigram là có thể đưa ra kết luận tên một người có phải người Việt hay không. (ví dụ tên “ho tu bao”, các unigram như “ho”, “tu”, “bao”, “bao ho”, “bao tu”, “ho tu” đều có thể là tên người nước ngoài, tuy nhiên trigram “ho tu bao” là tên một giáo sư người Việt.
Các trường hợp tên “nhập nhằng” khó dự doán, thường là tên có hai từ có cả tên người Việt lẫn nước ngoài từ tập dữ liệu đào tạo thì hệ thống phải dựa vào các tri thức khác để nhận biết: ví dụ phát hiện ngôn ngữ Vietnamese trong profile Linkedin, trường, viện đã từng học tập hay làm việc (các nhà khoa học gốc Việt có khả năng học và làm việc tại trường Việt Nam).
Qua thử nghiệm dựa trên một mẫu 10.000 profile lấy từ hệ thống Linkedin mà tên trên Profile có ít nhất 1 từ trong 16 họ Việt thông dụng từ trang Wikipedia “Họ_người_Việt_Nam”, thuật toán VietName Detection của BDAVO đã tăng độ chính xác từ 71% lên 93% trong việc phát hiện 1 profile trên linkedin có phải là người Việt hay không.
Trong năm 2019, giới khoa học Việt Nam có bàn luận về một nghiên cứu “A standardized citation metrics author database annotated for scientific field” của một nhóm giáo sư bên Mỹ kèm database khoảng 100.000 nhà khoa học có nhiều trích dẫn nhất và danh sách 40 nhà khoa học gốc Việt trong danh sách này. Thuật toán phát hiện tên người Việt của BDAVO đã tìm ra hơn 60 nhà khoa học có thể là người gốc Việt trong danh sách. Điều này thể hiện sự vượt trội hơn 30% khả năng phát hiện tên người Việt so với các phương pháp đơn giản.
Phát hiện mối liên hệ chuyên ngành
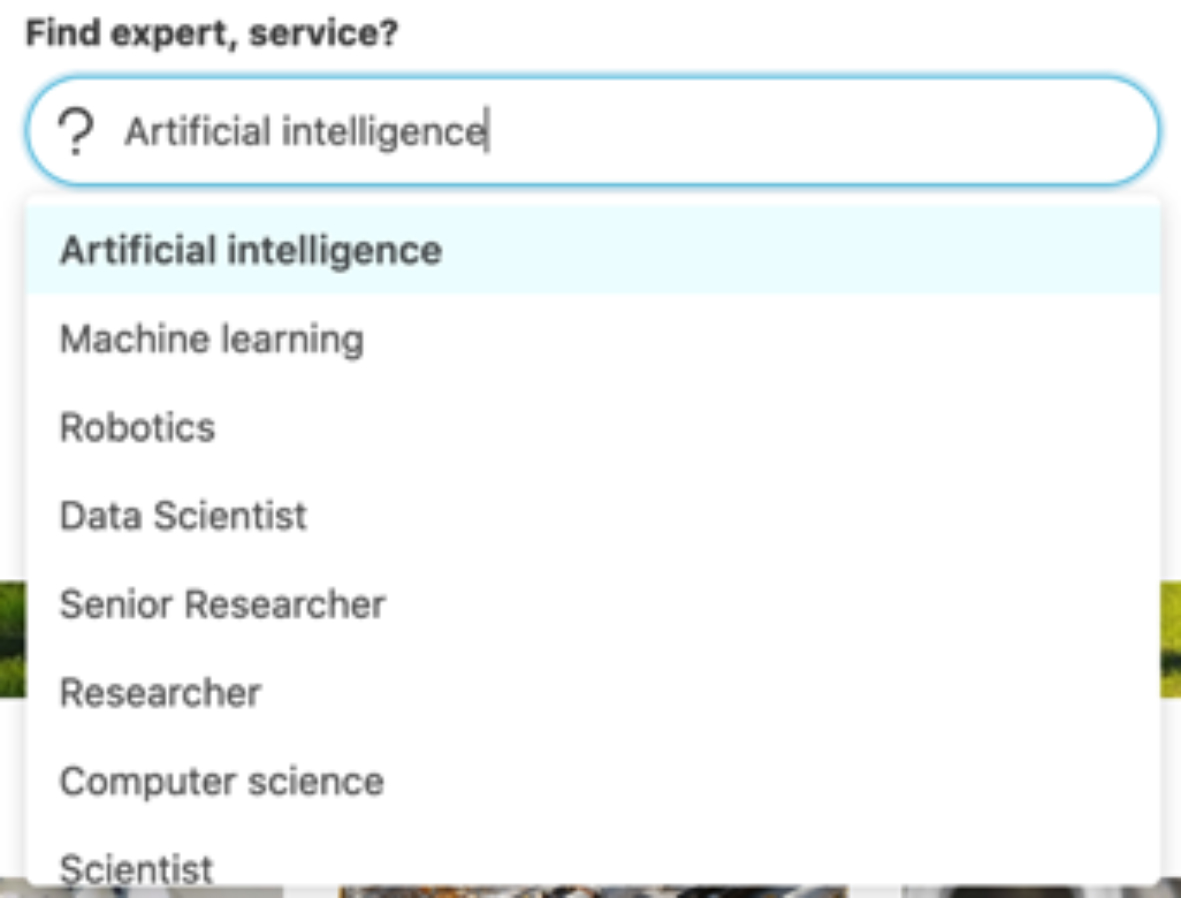
Trong các cơ sở dữ liệu, khi tìm kiếm thông tin với các từ khóa, phần lớn các hệ thống tìm kiếm thông tin đều đưa ra các kết quả nếu dữ liệu khớp với truy vấn của người sử dụng. Tuy nhiên có hạn chế là không phải một profile chuyên gia nào cũng cung cấp đầy đủ thông tin của mình. Do đó, việc sử dụng các tính năng suy diễn (inference), hệ thống xử lý thông tin hoàn toàn có thể “làm giàu” thêm profile chuyên môn của các chuyên gia hay gợi ý thêm từ khóa tìm kiếm hỗ trợ cho người sử dụng tìm kiếm được chuyên gia mình cần. Ví dụ khi nói đến “Artificial Intelligence” (trí tuệ nhân tạo) người sử dụng cũng có thể quan tâm đến các lĩnh vực liên quan như Machine learning (học máy), Robotics. Hay “Quantitative Analytics” (phân tích định lượng) thường áp dụng tại trong “Bank” (ngân hàng) hay “Finance Service” (dịch vụ tài chính).
Có hai cách chính để phát hiện mối quan hệ này là (1) Sử dụng một bộ Tri thức phân tầng đã được xây dựng sẵn (Ontology) (2) Sử dụng phương pháp thống kê Cùng xuất hiện trong ngữ cảnh (Collocation), tính “tỉ lệ giống nhau – likelihood ratio” giữa các ngành nghề trong dữ liệu đào tạo. Trong trường hợp của BDAVO, chúng tôi cố gắng kết hợp cả hai cách để bổ sung cây tri thức phân tầng với các chuyên ngành cây tri thức còn thiếu.
Với Ontology định nghĩa sẵn, ví dụ như “ACM Computing Classification System (https://dl.acm.org/ccs)”, nếu một chuyên gia ghi trong profile ”Machine Translation” (dịch máy) thì Ontology sẽ giúp hệ thống suy diễn ”Machine Translation” là lớp con của “Natural language processing” (xử lý ngôn ngữ tự nhiên). Lớp này lại là lớp con của “Artificial Intelligence”. Vì vậy khi tìm kiếm từ khóa “Artificial Intelligence” thì người truy vấn sẽ vẫn tìm được profile của chuyên gia này.
Tuy nhiên việc có được một bộ tri thức phân lớp chuẩn không phải dễ trong rất nhiều lĩnh vực chuyên môn. Vì vậy, phương pháp xây dựng mối quan hệ giữa các chuyên ngành dựa trên thống kê dữ liệu hay được sử dụng để xây dựng được bộ tri thức lớn cần ít tương tác thủ công. Hình minh họa kết quả gợi ý chuyên ngành “Artificial intelligence” với các chuyên ngành liên quan hay xuất hiện cùng nó trong các bộ dữ liệu thống kê.
 Sắp xếp thứ tự chuyên gia trong kết quả tìm kiếm
Sắp xếp thứ tự chuyên gia trong kết quả tìm kiếm
Khi truy vấn một cơ sở tri thức các Chuyên gia, hệ thống tìm kiếm có thể trả về hàng nghìn kết quả (ví dụ tìm chuyên gia Việt trên thế giới trong lĩnh vực Kinh tế “Economics” có thể có hàng nghìn người). Việc xác định các trọng số để các chuyên gia có chuyên môn cao hay có tầm ảnh hưởng lớn trong lĩnh vực được hiện lên trên trong các kết quả tìm kiếm sẽ giúp việc lựa chọn chuyên gia hiệu quả hơn. Các yếu tố hay hệ số để xác định trọng số tổng hợp đánh giá chuyên gia rất đa dạng. Có thể vị trí là trong công việc, học hàm, học vị, thanh danh nơi học tập, làm việc, hệ số trích dẫn, số công bố khoa học, phát mình, H-Index… Khi kết hợp hai hay nhiều trọng số trên và dựa vào các dữ liệu huấn luyện (training set) ta có thể tạo ra các ràng buộc để xác định các hệ số của hàm xếp hạng.
Có thể minh họa bằng việc xây dựng hàm xếp hạng qua một ví dụ rất đơn giản sau: Nếu gọi giá trị xếp hạng theo Academic Title của một chuyên gia là t, giá trị ranking theo nơi học tập, làm việc là u, hàm xếp hạng tổng hợp là R(t,u). Dựa trên các bảng xếp hạng trên thế giới, các phân cấp mức độ trong mỗi ngành nghề và các đánh giá của các chuyên gia, phản hồi từ người dùng hàm R(t,u) sẽ được tạo ra để áp dụng sắp xếp các chuyên gia trong hệ thống.
Ví dụ, trong lĩnh vực học thuật và nghiên cứu (academic), các vị trí thứ hạng như bảng sau:
| Academic Title | Rank value |
| Professor | 1 |
| Associate Professor | 2 |
| Assistant Professor | 3 |
| Post-doc/Scientist | 4 |
| Doctor/Ph.D. | 5 |
| Master | 6 |
| Bachelor | 7 |
Ví dụ 10 trường đại học hàng đầu thế giới theo đánh giá của Times Higher University ranking năm 2021.
| University | Rank value |
| University of Oxford | 1 |
| Stanford University | 2 |
| Harvard University | 3 |
| California Institute of Technology | 4 |
| Massachusetts Institute of Technology | 5 |
| University of Cambridge | 6 |
| University of California, Berkeley | 7 |
| Yale University | 8 |
| Princeton University | 9 |
| The University of Chicago | 10 |
Dựa theo các các đánh giá của con người (ví dụ sau chỉ là giả định), ta có thể xây dựng được tập ràng buộc sau:
| Human assertion | Constraints |
| Giáo sư trường thứ hạng 1 có vị trí cao hơn giáo sư trường thứ hạng 5 | R(1, 1) > R(1,5)
|
| Giáo sư trường thứ hạng 1 có vị trí cao hơn Tiến sĩ trường thứ hạng 1 | R(1, 1) > R(5,1)
|
| Giáo sư trường thứ hạng 5 có vị trí cao hơn Tiến sĩ trường thứ hạng 1 | R(1,5) > R(5, 1)
|
Dễ thấy với hàm R= w1* t + w2 * u, w1=-2, w2= -1 các điều kiện trên được thỏa mãn. Sau khi hàm R được xây dựng, ta có thể sử dụng nó để sắp xếp thứ tự các chuyên gia. Hàm R chỉ là tương đối và sẽ dần được hiệu chỉnh khi có nhiều phản hồi của người sử dụng, ví dụ dựa trên các Click hay Profile view của hệ thống.
***
Các công cụ tìm kiếm, mạng xã hội như Google, Linkedin, Facebook là công cụ cho toàn thế giới sử dụng và phát triển từ nước ngoài nên không thể tùy chỉnh cho riêng cộng đồng người Việt. Các hệ thống mạng xã hội, máy tìm kiếm của Việt Nam chưa có khả năng cạnh tranh về công nghệ và tính năng đối với các ứng dụng toàn cầu trên.
Nguồn cơ sở dữ liệu từ các hội, nhóm người Việt trên thế giới rất hạn chế việc truy cập và không có khả năng tự động cập nhật, không có các giao diện thân thiện với người dùng và chắc chắn thiếu các tính năng gợi ý thông mình và phát hiện mối liên hệ giữa các thực thể giữ liệu (ví dụ chuyên ngành liên quan) hay xử lý đa ngôn ngữ để việc khai thác nguồn dữ liệu được hiệu nhất.
Hy vọng với một số phương pháp xử lý dữ liệu từ dự án BDAVO và các dự án tương tự khác sẽ giúp Việt Nam sớm có một nguồn Cơ sở dữ liệu tập trung và đầy đủ về các nhà khoa học người Việt trong và ngoài nước để phục vụ cho việc tìm kiếm, gợi ý nguồn nhân lực phù hợp với công việc chuyên môn.